
9 LLM на обработке 10 000 кластеров: кто справился, а кто потерял половину данных
Мы испытали девять языковых моделей на задаче, с которой сталкивается каждый SEO-специалист в крупных проектах.
Семантику собирали для отечественной e-commerce площадки из топ-10. Отдали нейросетям 28 837 реальных поисковых запросов из категории «одежда и обувь». Целью было обработать хотя бы 10 000 кластеров.
В результате внедрили ИИ-решения для SEO-оптимизации, и работы заняли всего 2 месяца против прогнозируемых 2 лет. Благодаря этому скорость продвижения интернет-магазинов выросла в 10 раз.
Результаты сравнения получили любопытные: самая популярная модель упустила 32% данных, а более дорогие — не показали качественной разницы. Рассказываем подробнее.

Задача: отделить коммерцию от мусора без потерь
Клиент — многокатегорийная торговая площадка, которой необходимы сотни тысяч теговых под реальный поисковый спрос.
На первый взгляд всё просто: список запросов из Key.so нужно рассортировать на годные коммерческие запросы (под которые создаем страницы) и «мусор».
На деле, мусор не всегда легко отловить и классифицировать.
Дьявол в деталях: «манго» — это фрукт или бренд одежды Mango? А «спецодежда» — часть названия товара или запрос к товарной категории? А еще важен контекст, в котором упоминается сам товар. Например, запрос может содержать название товара, но по смыслу быть информационным. Этих и других тонкостей в нашем массиве запросов — тысячи.
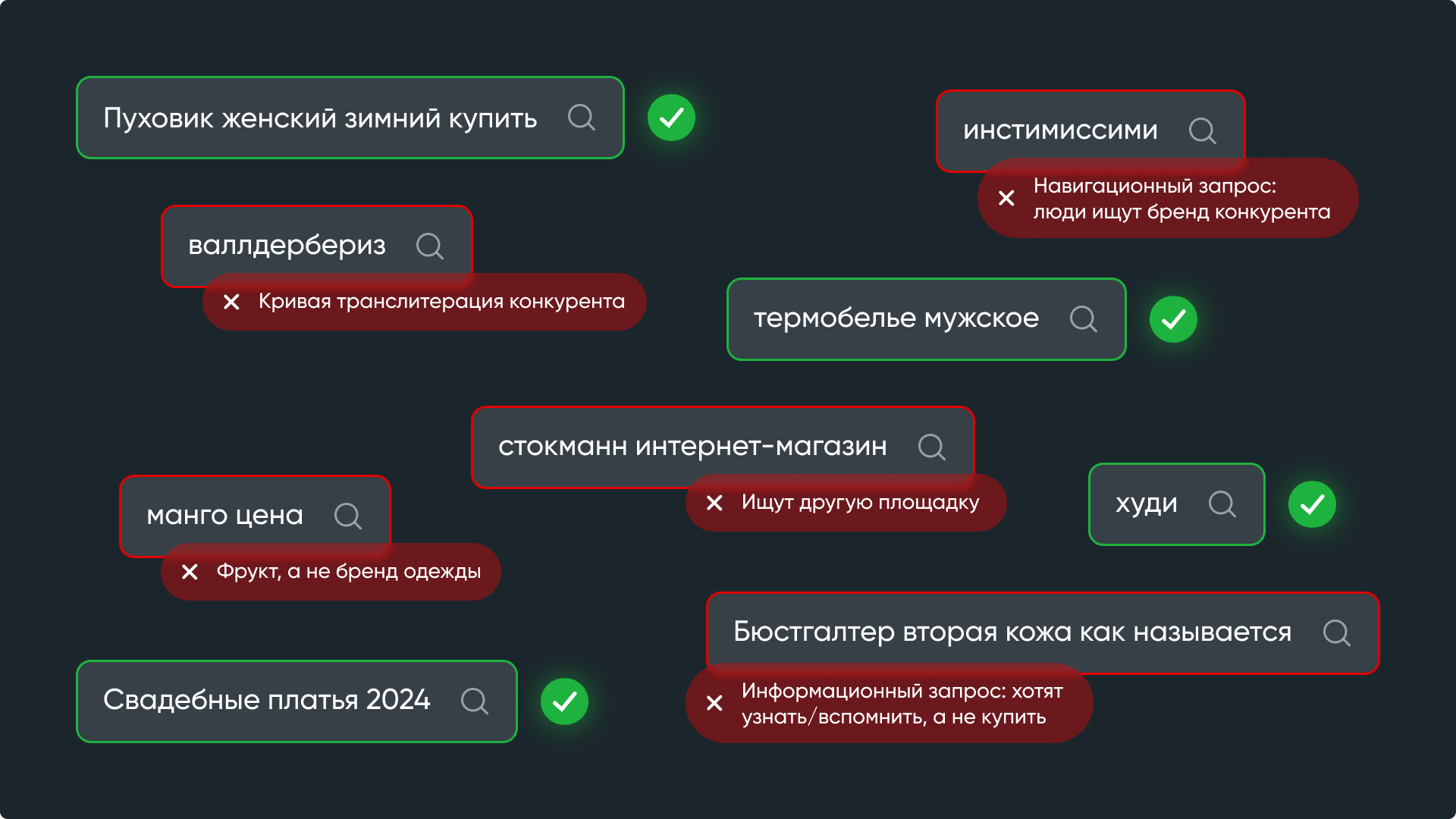
Как тестировали
Каждую модель прогоняли через одинаковый промпт и сравнивали результат с эталонной разметкой, которую наш SEO-специалист обычно делал три месяца.
Вот какие параметры фиксировали:
- время обработки 10 000 строк в минутах;
- цену обработки всего массива в долларах;
- процент мусора, который модель пропустила как коммерческие запросы;
- процент коммерческих запросов, ошибочно отправленных в мусор;
- долю данных, потерянных из-за сбоев API.
На основе этих параметров оценивали эффективность модели в целом.
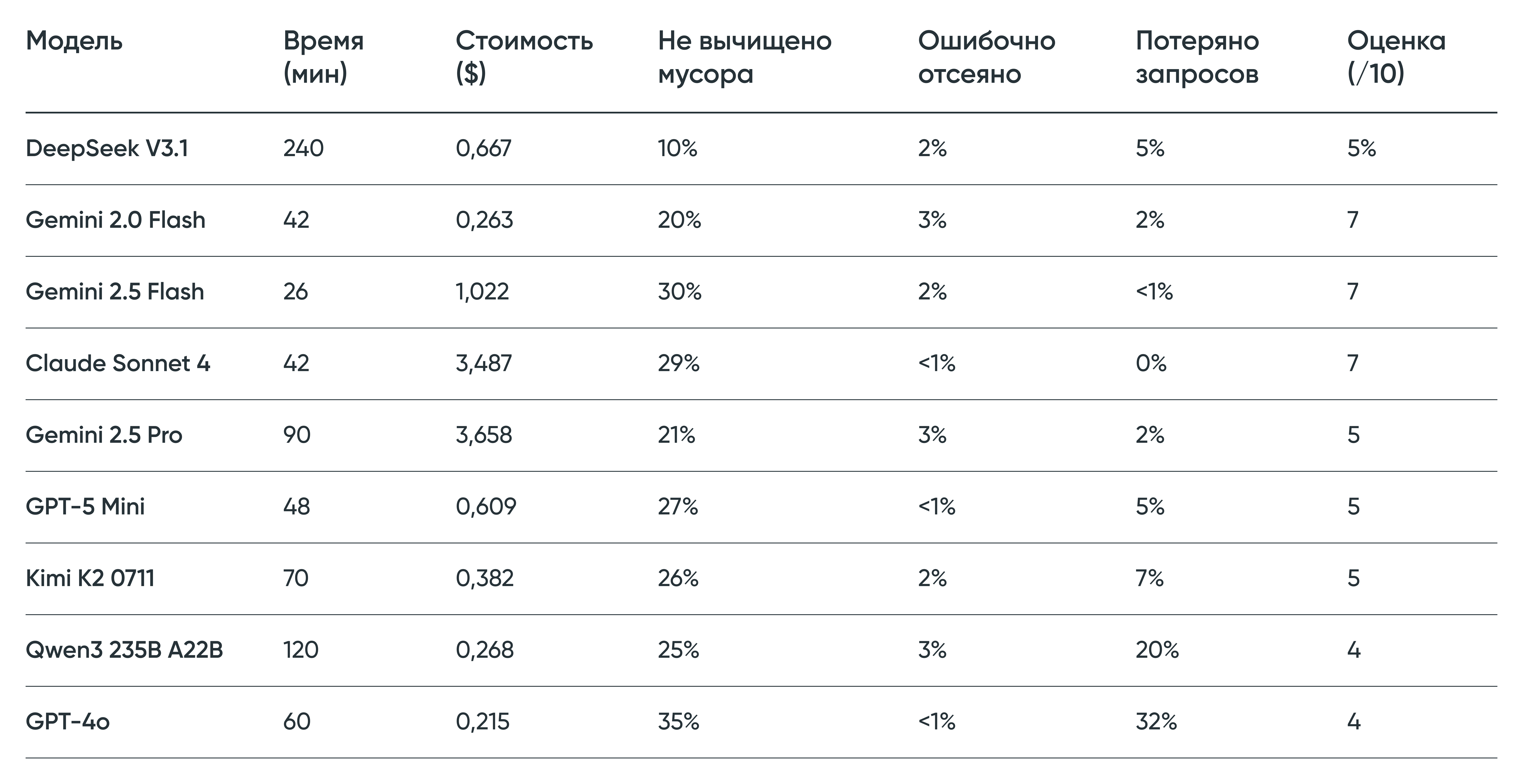
Результаты и важные наблюдения
Наш рейтинг нейросетей для конкретной задачи выглядит так:
В процессе мы поняли два ключевых момента:
1. Недостаточно просто выбрать модель — критически важны настройки. Параметр temperature (уровень креативности) напрямую определяет, насколько строго модель следует техническому заданию.
DeepSeek изначально работала на 6 из 10: считывала упоминания многих брендов как навигационный мусор. После снижения «температуры» с дефолтных значений до 20% качество работы выросло, и наша оценка — тоже.
2. Промптинг решает. Даже лучшая модель работает плохо без правильной инструкции. У нас процесс доработки промпта был цикличным: получили результат от нейросети → сравнили с эталоном → классифицировали типы ошибок → доработали промпт → повторили цикл.
Например, изначальный промпт «привяжи теговую страницу к категории» трансформировался в такой: «если в запросе есть явный тип изделия (колье, браслет), выбери соответствующую товарную категорию из списка, игнорируя модификаторы: материал/вставку/пол/стиль/цвет/размер (жемчуг, гранат, мужские, женские и так далее)».
В результате структурные ошибки DeepSeek упали с 49% до 7%. А вот у GPT при тех же доработках доля ошибок не изменилась: модель хуже понимает сложные инструкции.
Наша классификация моделей
Годятся для работы
DeepSeek V3.1 — самая дотошная
Показывает лучший результат по чистке мусора среди всех протестированных моделей. И минимум ошибок при определении коммерческих запросов.
Где косячит: консервативно относится к брендам — отправила в мусор «авалон», «некст», «asos», «2mood одежда», хотя это валидные бренды из ассортимента. При этом «burberry» пропустила корректно. Странно обработала запрос «спецодежда» — определила как товар, хотя это скорее товарная категория.

Gemini 2.0 Flash — универсальный боец
Лучшее соотношение скорости, цены и качества. Работает в 5 раз быстрее DeepSeek и стоит столько же. Да, пропускает вдвое больше мусора (20% против 10%), но для многих задач это приемлемый компромисс.
Где косячит: пропустила «maag» (непонятная транслитерация) как коммерческий запрос, не распознала «интимиссими» как чужой бренд. Но с основными товарными категориями работает стабильно.

Gemini 2.5 Flash — для горящих дедлайнов
Максимальная скорость и минимальные потери данных. Но в обмен на более низкое качество проработки и цену в четыре раза выше Gemini 2.0 Flash.
Где косячит: оставляет много мусорных строк из исходного массива.

Неоправданно дорогие
Claude Sonnet 4
Стабильный API, который не теряет данные — это плюс. Но за $3,487 получаем качество чистки хуже, чем у Gemini 2.0 Flash за $0,263. Переплата не дает преимуществ по ключевым метрикам.
Gemini 2.5 Pro
Ситуация аналогичная: цена выше в 14 раз по сравнению с Gemini 2.0 Flash. При этом скорость вдвое ниже, а качество сопоставимое. Переплата экономически не оправдана.

Ненадежные
Китайские модели
Qwen3 235B A22B: цена заманчивая ($0,268 за 10 000 строк), но модель теряет 20% данных. Каждый пятый запрос просто исчезает из результата.
Kimi K2 0711: значительно лучше — теряет 7% данных за $0,382. Но это все равно означает, что из каждых 100 000 запросов вы не получите обратно 7 000.
Для массовой обработки семантики такой уровень недопустим. Финансовая экономия не компенсирует риск упустить важные данные.
Потеря потерь
GPT-4o
Это история о том, как привлекательные цифры на бумаге оборачиваются катастрофой на практике. Из 28 837 запросов модель вернула только 15 954 — около половины данных просто исчезло. При этом 32% обращений к API завершились сбоями.
Парадокс в том, что те запросы, которые GPT-4o успел обработать, он обработал качественно — меньше 1% ошибок классификации. Но это не имеет значения, когда утеряна половина массива.

Стоит ли автоматизация того
Кратко — да. Но есть нюансы.
Ниже сравнили стоимость ручной разметки семантического ядра и автоматизированной работы (чистка лучшей ИИ + проверка специалистом).
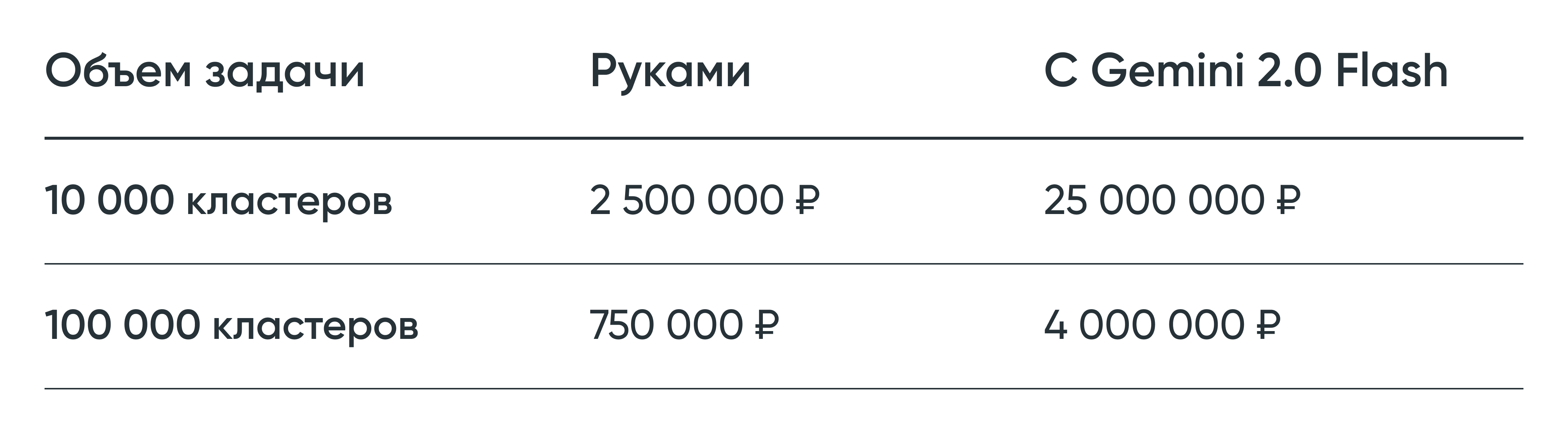
Экономия не только в деньгах — задача, которую специалист делает три месяца, с нейросетью решается за несколько дней. Получается ускорение в 10–15 раз.
А вот и нюанс: есть порог эффективности. Автоматизация окупается от 1 000 кластеров. Если задача мельче — настройка системы, промптов и проверка результата обойдутся дороже, чем просто сделать руками.
Не идеализируем LLM
Языковые модели хорошо решают задачи, которые можно формализовать:
- массовая классификация запросов по заданным критериям,
- генерация заголовков и описаний по шаблонам,
- отсев очевидного мусора.
Но есть вещи, с которыми нейросети не справляются:
Понимание бизнес-контекста. Модель не знает, что для конкретной площадки важнее — бренд Burberry или категория «свитшоты с принтом». Она не понимает маржинальность товарных групп и приоритеты развития.
Учет сезонности. Запрос «купальники» в июне и декабре имеет разную коммерческую ценность, но модель этого не видит.
Настройка под специфику ниши. Каждый проект требует адаптации промпта под особенности ассортимента, конкурентов, целевой аудитории. Это задача специалиста.
Реалити-чек. Нейросеть может технически правильно классифицировать запрос, но при этом предложить решение, которое нерелевантно для бизнеса.
Оптимальная схема работы:
- Нейросеть обрабатывает 90-95% массива по заданным правилам.
- SEO-специалист проверяет и дорабатывает оставшиеся 5-10%, принимает стратегические решения, настраивает промпты под изменения в проекте.
Как все-таки выбрать
Вот упрощенная схема:
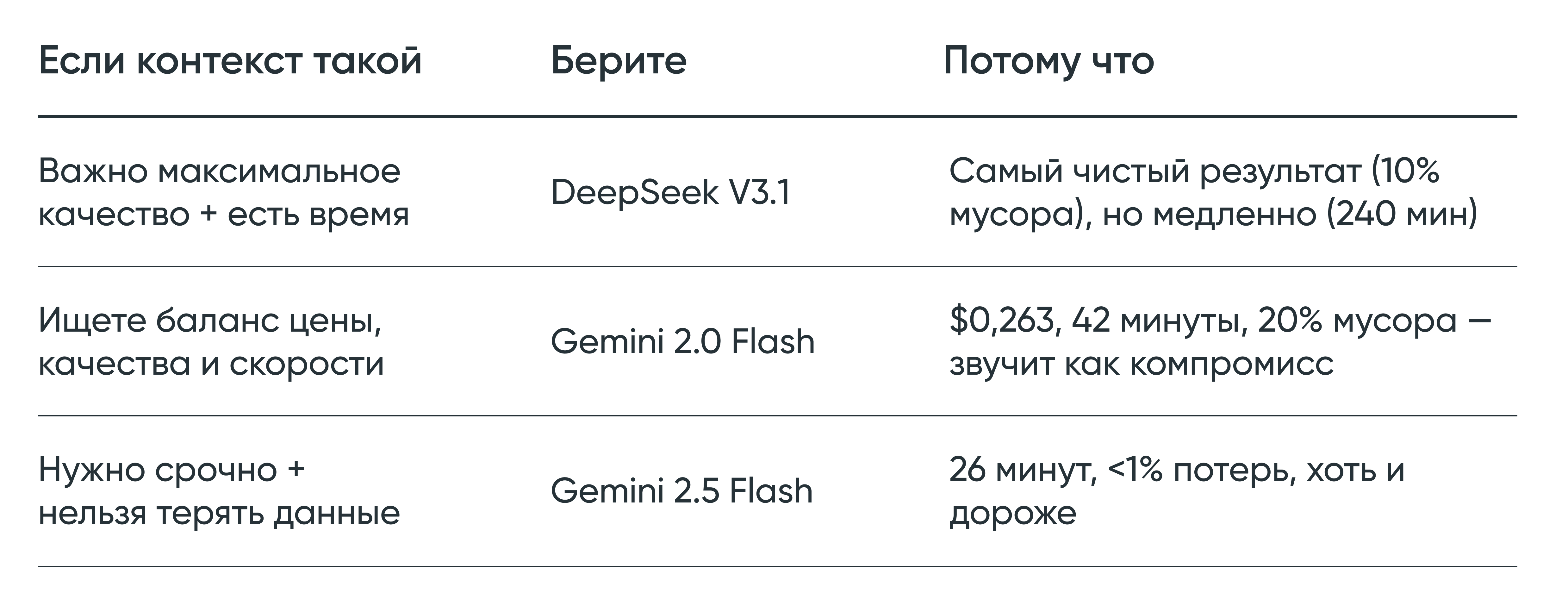
А эти варианты можно сразу отбросить:
❌ Популярный GPT-4o. Потеря почти половины данных делает модель непригодной для массовой обработки, несмотря на низкую заявленную стоимость.
❌ Китайские модели (Qwen3, Kimi). Низкие цены не компенсируют риск потерять каждый пятый–седьмой запрос из массива.
❌ Дорогие модели (Claude Sonnet 4, Gemini Pro). Переплата в 13–14 раз не даст ощутимого прироста по ключевым показателям.
Чек-лист для внедрения
Несколько советов из нашего опыта:
- Установите temperature на 20%. Это поможет модели меньше фантазировать и точнее следовать инструкциям.
- Циклично улучшайте промпт. Возьмите небольшую выборку (500–1000 запросов), разметьте вручную, прогоните через модель, сравните с эталоном и выявите паттерны ошибок, доработайте промпт, повторите.
- Проверяйте 5–10% результата руками. Случайная выборка после автоматической обработки поможет отловить системные ошибки и странности в работе модели.
- Мониторьте потери данных. Всегда сверяйте количество строк на входе и выходе. Если модель вернула меньше запросов, чем получила — это сигнал о проблеме.
И главное. До 1000 кластеров обрабатывайте руками. Автоматизация окупается на больших объемах. Небольшие задачи быстрее и дешевле решить без настройки промптов и внедрения систем.

Как мы в 3 раза увеличили трафик сайта интернет-магазина запчастей: кейс Ridestyle.ru Статья
Топ-10 распространенных ошибок в SEO-продвижении, которые делают почти все Статья
Сложную дорогу осилит только идущий. Кейс успешного SEO-продвижения интернет-магазина B2B Статья
«Телега» временно ограничила вход из-за наплыва новых пользователей Статья
В MАХ добавили раздел «Для бизнеса»: компании могут получить доступ к созданию каналов и ботов Статья
Операторы связи в России отключили оплату сервисов Apple со счёта мобильного телефона по требованию Минцифры Статья
VK Реклама выпустила обновление «Прямых сделок» Статья
Wildberries уравняет комиссии для селлеров из России и Китая Статья
В сервисах аренды самокатов появится верификация через «Госуслуги» Статья





