Как закрыть «лишние» страницы сайта от индексации в поисковиках: 3 способа и пошаговая инструкция
Термин «Индексация» означает действия поисковых роботов, в результате которых они «считывают» и сохраняют в базы Яндекса и Гугла содержимое сайта: картинки, видеоролики и другие вебматериалы.
Когда в индекс попадают только полезные материалы, в поисковой выдаче по нужным запросам будут выходить только релевантные веб-ресурсы. Частая ошибка при оптимизации сайта — не исключать страницы, которые не следует показывать в результатах поиска. В этой статье покажем, как скрывать их от индексации и рассмотрим все способы.
Почему нельзя индексировать весь сайт целиком
Во-первых, для Интернет-пользователей наличие в выдаче бесполезного контента затрудняет поиск нужной информации, как следствие — поисковики понижают сайты с «ненужными» страницами в выдаче.
Во-вторых, есть требование поисковиков к уникальности контента. Когда какая-либо информация дублируется на разных веб-страницах — для роботов она уже не уникальная, поэтому без настройки запрета не обойтись, если:
- У вас версия сайта для мобайла на отдельном домене
- Вы тестируете сайт на другом домене — поисковые роботы также могут принять одинаковые страницы за дубликаты.
В-третьих, у поисковиков есть ограничение по количеству веба для сканирования, для каждого ресурса — своя цифра, она называется краулинговый бюджет. Когда он уходит на редиректы, спам и прочую фигню, его может не хватить на действительно ценные материалы.
В-четвертых, когда вы кардинально меняете дизайн и структуру, лучше скрыть сайт, чтобы он за это время не потерял позиции в поиске из-за низких показателей юзабилити.
Что нужно закрывать от индексации
Закрыть от индексации рекомендуем следующие страницы.
Дубли
Это страницы сайта, единственное различие которых — URL-адреса. Когда несколько одинаковых или почти одинаковых веб-страниц попадают в индексирование, они конкурируют между собой, в результате чего сайт серьезно теряет позиции в выдаче.
Во всех случаях, когда контент открывается не по одному URL-адресу, а по нескольким, система считает его дублем и пессимизирует сайт, на котором находится такой контент.
Кроме того, это сильно влияет и на скорость обхода сайта программами, так как нужно просмотреть уже не одну страницу, а несколько, то есть краулинговый бюджет тратится не по назначению.
Документы для скачивания
Примеры: политика конфиденциальности, обучающие материалы, руководства.
Когда заголовки документов появляются в выдаче выше, чем веб-страницы с ответом на тот же запрос, это плохая идея. Человек может скачать документ и не пойти дальше изучать контент.
Веб в разработке
Они пока не решают задачи пользователей и не готовы к конкуренции — ни к чему показывать их поисковым роботам, иначе рейтинг сайта в поисковиках может упасть.
Технические страницы
К ним относится всё, что относится к служебным целям, но не информативно с точки зрения SEO для пользователей. Примеры:
- Результаты поиска по сайту
- Формы связи и регистрации
- Личный кабинет
- Корзина пользователя
- Пагинация — с ней не всё однозначно, поэтому этот вид разберем отдельно
Как проверить, корректно ли работает запрет индексации
Прежде чем переходить к инструкции, важный момент: ни один способ не гарантирует на 100%, что поисковые роботы не будут игнорировать запрет. Поэтому всегда проверяйте результат в панели веб-мастеров Google Search Console и Яндекс.Вебмастер.
В первом инструменте при настройке запрета должен быть статус, как на скриншоте ниже:
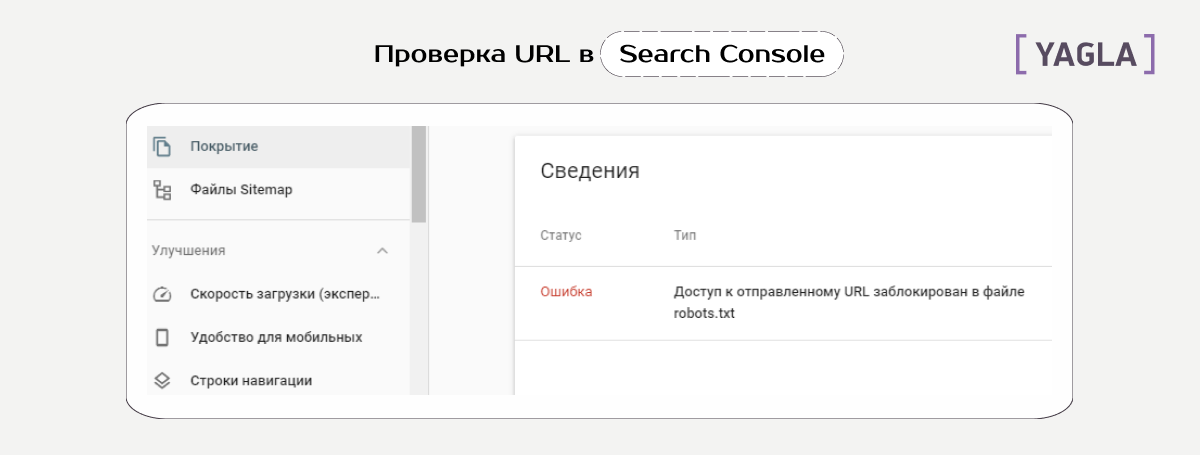
В Вебмастере Яндекса зайдите в раздел «Индексирование» и проверьте статус любого URL.
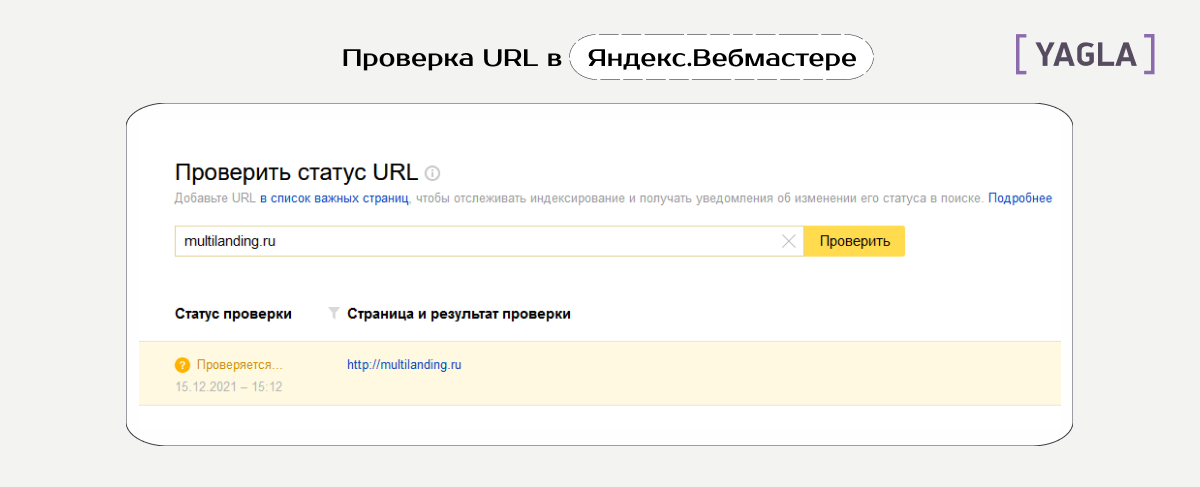
Скрыть от сканирования можно как отдельные веб-страницы, фрагменты и разделы сайта, так и весь сайт целиком. Далее рассмотрим все способы по порядку и разберем, когда какой лучше применять.
Как закрыть страницы от индексации в robots.txt
Robots.txt — самый распространенный способ. Вы используете текстовый файл под этим именем, чтобы задать в нем веб-страницы, которые поисковые программы будут посещать в ходе индексации и исключить те, которые посещать не нужно. То есть для поисковиков файл robots служит ориентиром.
Шаг 1. Найдите или создайте robots.txt
Первое, что нужно найти — корневую папку сайта. Именно туда загружаются все каталоги и файлы сайта. Для этого зайдите в панель управления хостингом, там вы увидите нужный домен и в блоке «Корневая директория» — путь.
Когда файла в корневой папке нет, это значит, что для поисковиков нет ограничений по индексации, и в выдачу может попасть какая угодно страница с сайта. Чтобы этого не допустить, откройте на компьютере пустой документ в формате txt, сохраните под этим именем и залейте.
Путь до домена — тот же. В панели управления хостингом нажмите кнопки «Каталог» — «Закачать» и загрузите, который создали.
Шаг 2. Пропишите список роботов, для которых работает запрет
Первая строка в документе будет такой, если вы хотите запретить индексацию для всех без исключения:
User-agent: *
Если, например, только Яндекс — такой:
User-agent: Yandex
Шаг 3. Примените директиву Disallow и укажите адрес
Через двоеточие напишите адрес. Выглядит это примерно так:
Disallow: /catalog/page.html
В этой схеме catalog означает раздел, page — адрес.
Чтобы запретить сканирование для всех поисковиков, кроме какого-то определенного, например, Гугла, задайте это в четырех строках подряд:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
Директива Allow позволяет Гуглу индексировать сайт.
Чтобы запретить индексацию целого раздела, нужно прописать его название со слешами:
Disallow: /catalog/
Чтобы поисковые роботы не посещали сайт целиком, в файле пропишите такие строки:
User-agent: *
Disallow: /
Мнение экспертов
Отчасти директивы Crawl-delay потеряли свою актуальность. Максим Ворошин, SEO-специалист MKlines, назвал случаи, когда условие в robots.txt может не сработать. Для Яндекса оно обязательное лишь отчасти: если на закрытый материал ведут несколько ссылок или идет трафик, есть вероятность, что он появится в индексе поисковика. Что касается системы Гугла — для появления закрытой страницы в поиске достаточно того, чтобы на неё вело много ссылок.
По опыту эксперта Алены Рыбиной, блогера SEOFY, Яндексу безразлично, как закрывать страницы от индекса — они в любом случае пропадут из базы. Ситуация, когда Гугл индексирует, несмотря на robots.txt, бывает не часто — как правило, поисковик придерживается инструкций индексации. Бывали и исключения, например, когда индексировались страницы плагинов и с динамическими параметрами, несмотря на то, что в настройке не было ошибок.
При этом, как отмечает Анастасия Шестова, руководитель направления поискового продвижения ИнтерЛабс, обычно количество таких страниц невелико и не является значимой проблемой.
Как закрыть страницы от индексации через метатег Robots
Если программы всё-таки индексируют веб из файла Robots.txt, есть альтернативный способ — директивы noindex и nofollow в метатеге Robots. Их нужно добавить в <head> страницы.
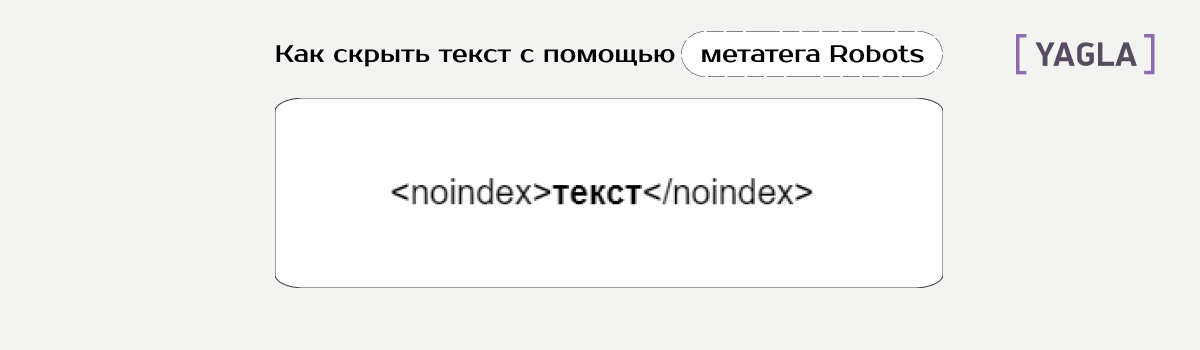
Способ метатега помогает скрыть:
- Конкретный кусок текста.
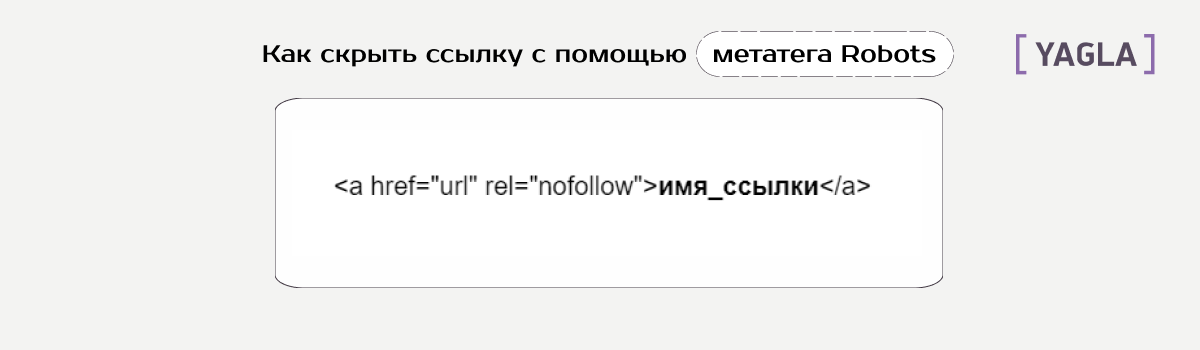
- Ссылку.
- Весь контент полностью.
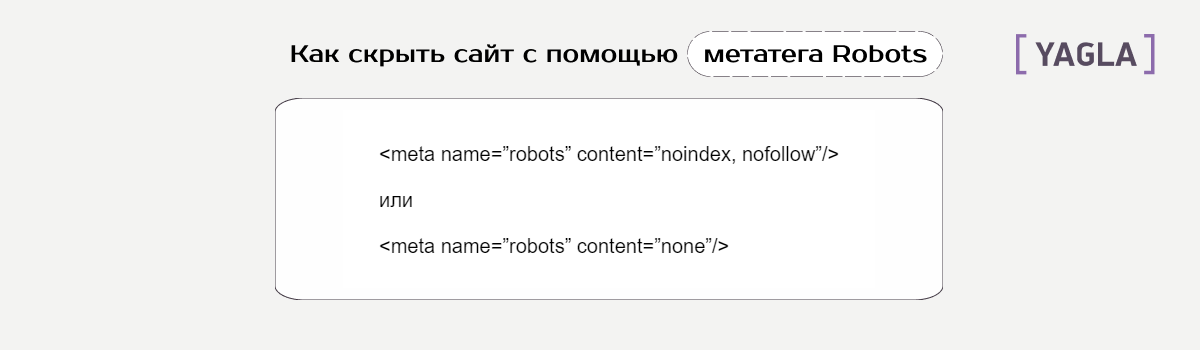
Разница между первым и вторым вариантом — во втором вы запретите индексацию, но при этом также обрубите передачу статического веса страниц.
Как правило, метатег Robots — самый простой способ запретить индексацию. Он работает 100% для всех поисковых систем. Однако если проверка в Search Console и Вебмастере показывает, что запрет индексации не действует, скопируйте в файл .htaccess следующий кусок кода:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
SetEnvIfNoCase User-Agent "^Aport" search_bot
SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot
SetEnvIfNoCase User-Agent "^msnbot" search_bot
SetEnvIfNoCase User-Agent "^Mail" search_bot
SetEnvIfNoCase User-Agent "^spider" search_bot
SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot
SetEnvIfNoCase User-Agent "^Robot" search_bot
SetEnvIfNoCase User-Agent "^php" search_bot
SetEnvIfNoCase User-Agent "^Snapbot" search_bot
SetEnvIfNoCase User-Agent "^WordPress" search_bot
SetEnvIfNoCase User-Agent "^Parser" search_bot
SetEnvIfNoCase User-Agent "^bot" search_bot
Метатег Robots удаляет из индекса быстрее, чем robots.txt, так как последний способ системы используют как рекомендацию, а не жесткое правило.Максим Ворошин, SEO-специалист MKlines
Как закрыть страницы от индексации через X-Robots-Tag
Этот способ запрещает индексацию контента определенного формата. Другое название — HTTP-заголовок на уровне сервера. Проще это реализовать через .htaccess, то есть с помощью таких строк в документе:
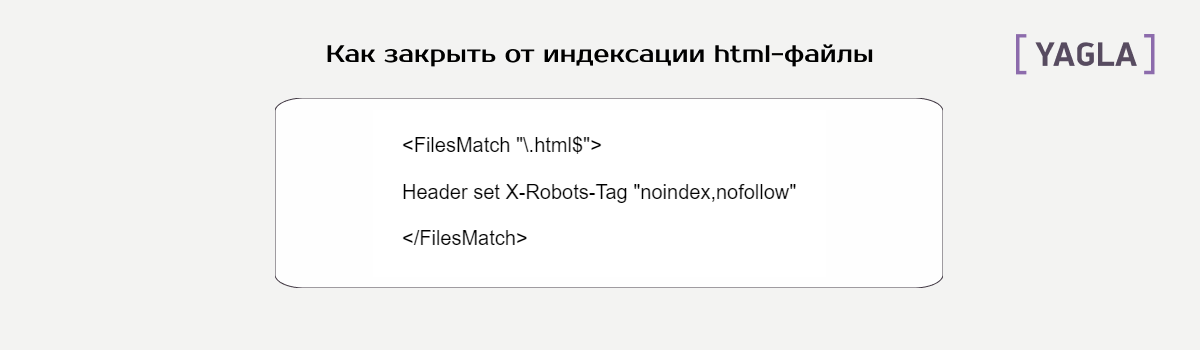
Это для html. А чтобы бот не не индексировал изображения на сайте, можно отключить форматы .png, .jpeg, .jpg, .gif:
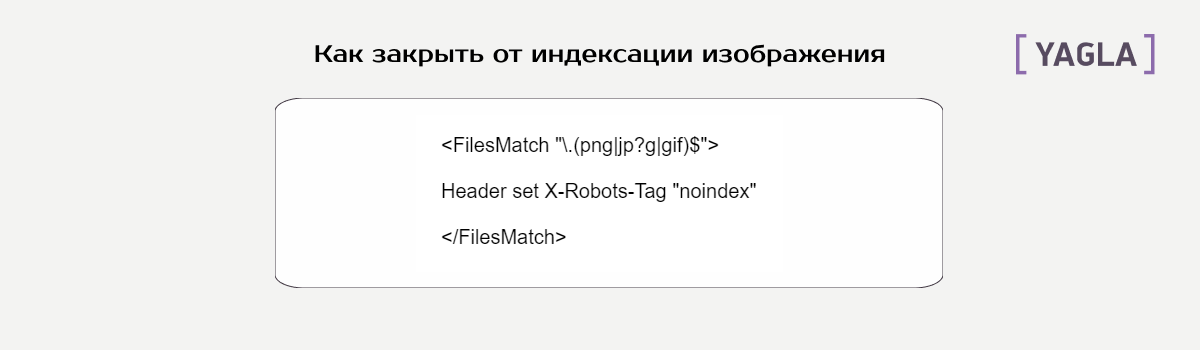
По аналогии в директиве FilesMatch можно использовать любой формат.
О методе заголовков на уровне сервера Google рассказывал еще в 2007 году. По словам эксперта Максима Ворошина, этот метод работает в 100% случаев, но используется реже остальных.
Важное преимущество — в том, что метод можно использовать как для html-страниц, так и для любого типа содержимого, например, файлов .doc и .pdf.
Как закрыть страницы пагинации от индексации
Нет единого мнения, стоит ли скрывать их от сканирования.
Аргумент «против» — актуальный для интернет-магазинов: риск, что товары не на первой странице каталога будут выпадать из индекса из-за низкой ссылочной массы.
Аргумент «за» — возможность появления дублей title на сайте.
Что касается настройки запрета для пагинации, перечисленные в статье способы не помогут. Оптимальный вариант — канонический способ rel="canonical" с указанием главной страницы категории. В этом случае поисковики обходят ссылки на страницах пагинации, но сами страницы не появляются в индексе.
Заключение
Если показывать в поиске все подряд материалы сайта, в том числе заведомо бесполезные для посетителей, сайт может серьезно «просесть» в выдаче по позициям. В том числе есть смысл ставить запрет на индексацию для всех страниц, которые пока не готовы к потоку пользователей.
Сделать это можно тремя способами:
- Прописать в документе robots.txt
- Применить директиву noindex
- Использовать HTTP-заголовок на уровне сервера
В то же время ни один способ не дает гарантии, что закрытые страницы не попадут в базы поисковиков, поэтому стоит дополнительно проверить результат по URL-адресам в сервисах Яндекс.Вебмастер и Search Console.
Категория 18+: в России появится доставка товаров по биометрии Статья
Новая функция Wildberries: теперь можно открыть совместный сбор денег на подарок Статья
Продвижение интернет-магазина в 2022-2023 году Статья
Сбер обновил GigaChat Audio: модель считывает интонацию и запоминает факты из диалогов Статья
Как обойти зарубежных селлеров на Wildberries без демпинга за счет локального визуала Статья
Реферальная программа: что это и как заработать на реферальных ссылках Статья
Переписки и документы пользователей Claude попали в поиск Google Статья
Кейс ASO для «Горздрава» и «36,6»: органика +50 %, ДРР -61,8 % Статья
Кейс: 149 заявок за 3 месяца в B2B-проектировании. Почему реклама не равно продажи? Статья





