Семантика в Яндекс.Директе: этапы, инструменты, чек-лист по оптимизации
Как собирать семантику для Яндекс.Директа, вы узнаете в этой статье.
Парсинг
Ручной способ
Вставляем словосочетание в Яндекс Wordstat:

Для фиксирования предлогов можно использовать оператор +.
Нам нужна вся выдача, на данный момент без фильтрации. Копируем её вместе со значениями частотности в таблицу Excel для удобства.
Чтобы получить как можно больше расширений, повторяем те же действия по каждой маске.
Рекомендации:
- Каждую смысловую группу лучше парсить отдельно, чтобы не запутаться;
- Копируйте все результаты от 1 показа и больше. Типичная ситуация — там, где Wordstat показывает 1, на самом деле 100-200 показов.
Далее — сбор подсказок Яндекса:
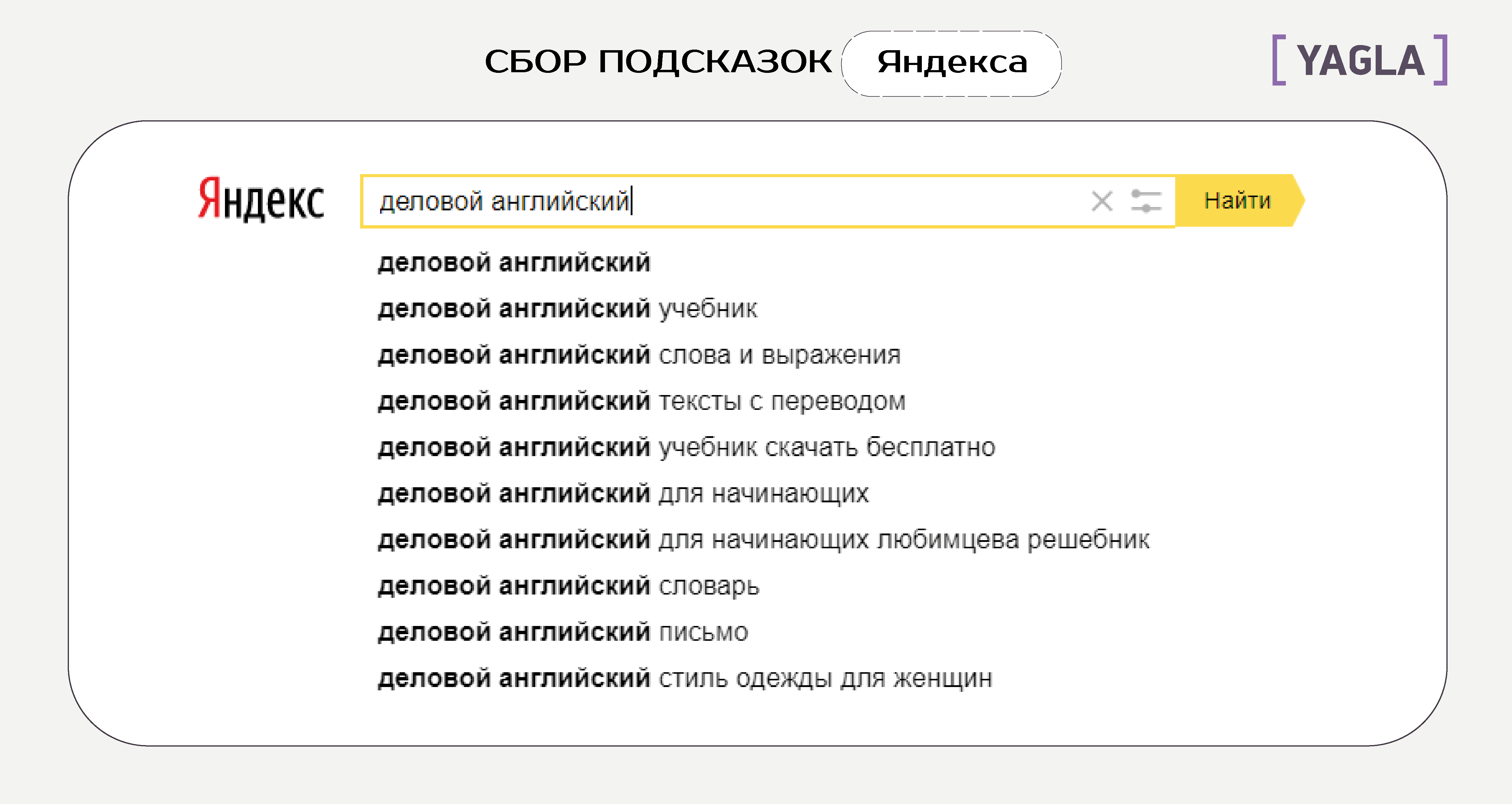
Каждый запрос дает отдельный набор подсказок. Весь список подсказок тоже добавляем в Excel.
Объединяем все расширения и подсказки по ним. Результат — статистически достоверная выборка со всеми уникальными низкочастотниками и минус-словами. Вероятность учесть все запросы и получить по ним чистый трафик высокая.
Автоматический способ
Избежать трудоемкой работы помогут инструменты для парсинга.
Самый популярный парсер ключевых слов Яндекса и других систем — Key Collector — дает такие возможности:
- Сбор информации напрямую с популярных источников
- Выбор региона и глубины поиска
Рекомендация: выбирайте глубину 2. Так вы сразу получаете не только результаты парсинга, но и дополнительную выдачу по каждому из них.
- Оценка фраз по стоимости продвижения, популярности, конкуренции, трафику и другим параметрам
- Экспресс-анализ содержимого сайта на соответствие СЯ + рекомендации по внутренней перелинковке
- Экспорт запросов из парсера в Excel и CSV
- Удобное табличное представление данных со всплывающими редакторами
Key Collector
Чтобы сделать парсинг в Key Collector, добавляем фразы:
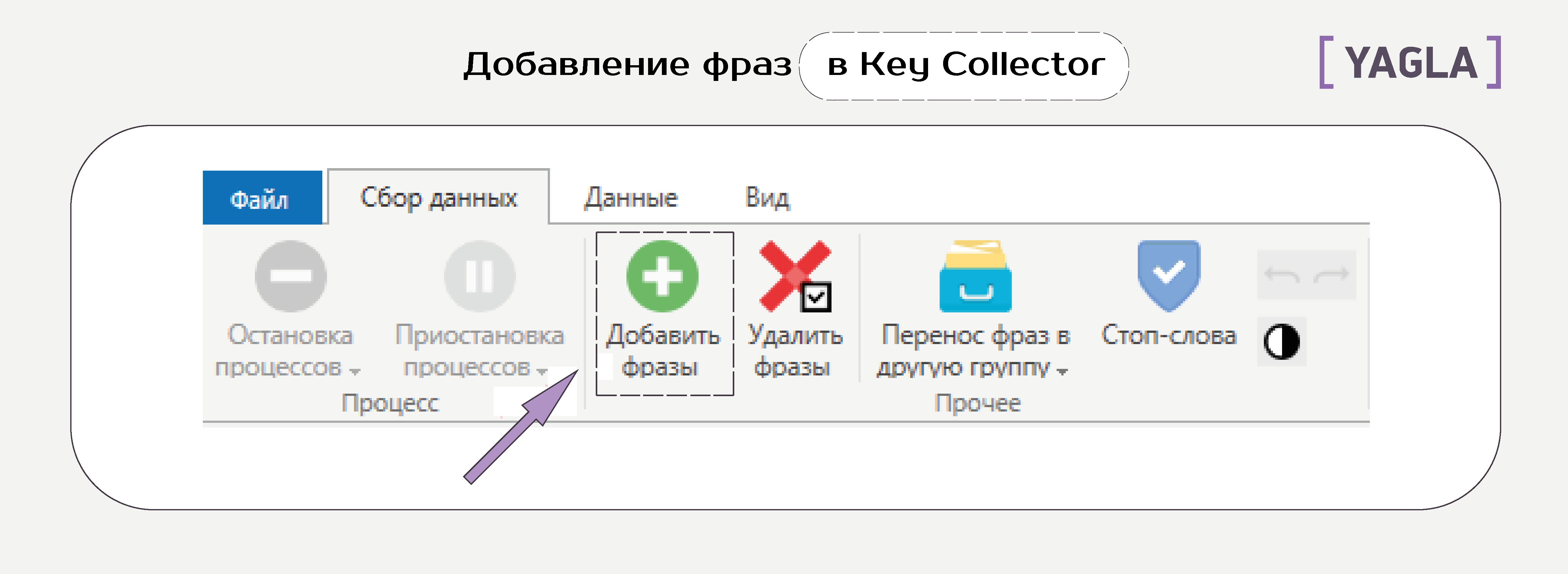
Запускаем парсер.
Вкладка Yandex.Wordstat
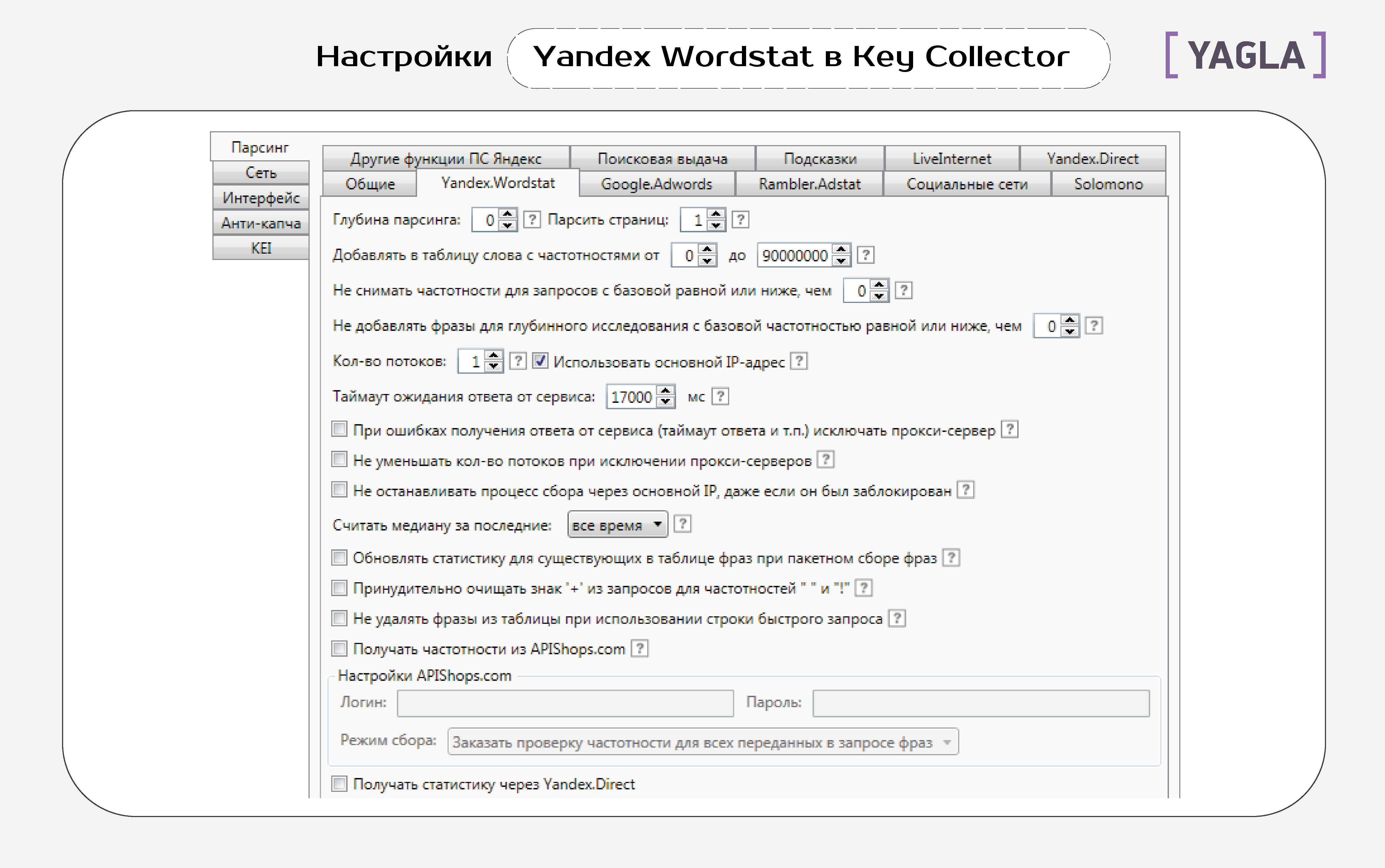
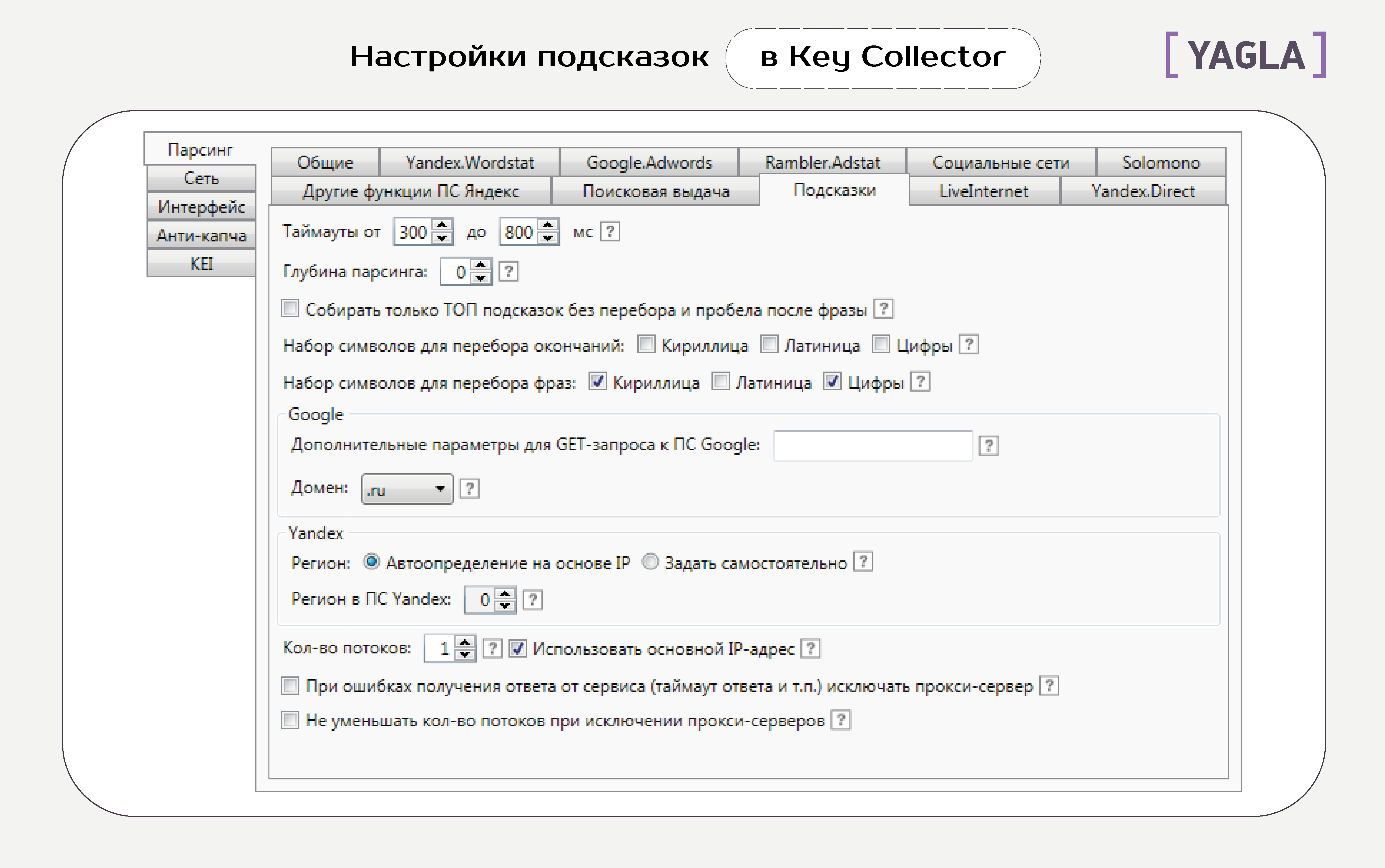
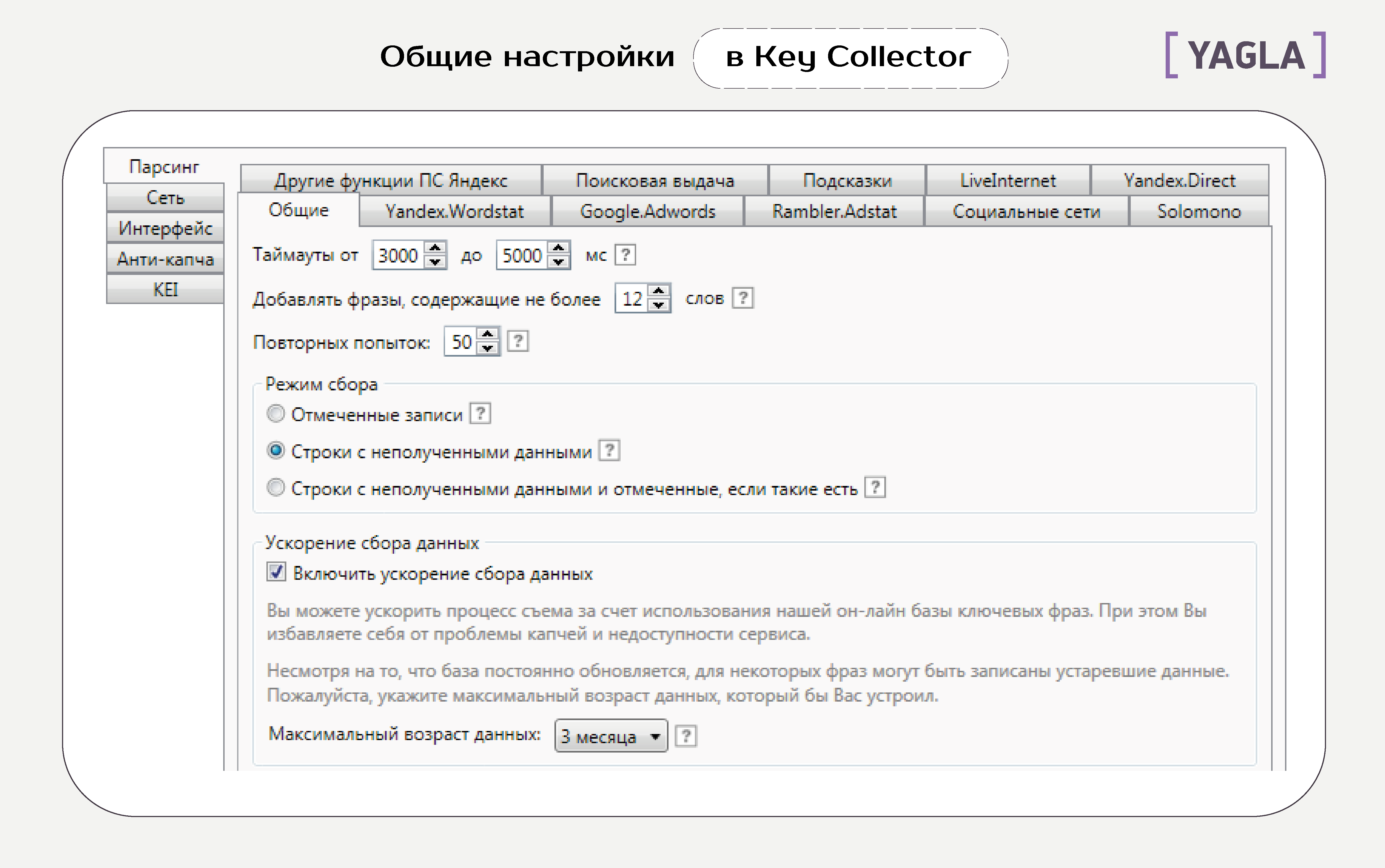
Вот что означают все эти опции.
Глубина парсинга. Количество обходов списка слов, которое делает программа для одного ключевика. С каждым разом растет количество слов и время на обработку.
Парсить страниц. Количество страниц в выдаче, которое просматривает программа. Максимум в Wordstat — 40, на каждой — до 50 фраз, то есть 2 тысячи результатов по одной фразе. Сервис предлагает такое количество лишь для высокочастотных запросов.
Добавлять в таблицу фразы с частотностями от ... до ... Мы задаем диапазон частотностей. Чтобы избежать потери важных ключевиков, используйте фильтрацию в таблицах данных.
Не снимать частотности для фраз с базовой равной или ниже, чем ... Это экономит время, трафик, а также позволяет снизить вероятность получения капчи, так как исключает из проверки заведомо неподходящие фразы.
Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем ... Это сокращает время на сбор информации за счет игнорирования фраз, у которых низкая базовая частотность.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер. При запуске процесса программа берет список прокси-серверов из настроек и работает с каждым. Можно увеличить скорость сбора информации, если удалять из очереди те, которые не отвечают на запросы или которым не отвечает сервис.
Не уменьшать количество потоков при исключении прокси-серверов. В нормальном режиме сервис сокращает количество потоков, чтобы не допустить перегрузку на еще не исключенных прокси-серверах. Можно это отключить.
Не останавливать процесс сбора через основной IP, даже если он заблокирован. В результате этого получение статистики какое-то время будет отвергаться, и возобновится, когда провайдер назначит новый IP.
Считать медиану за последние ... месяцев. Программа вычисляет значение по этому периоду при сборе данных о сезонности.
Обновлять статистику для существующих в таблице фраз при пакетном сборе фраз. Опция позволяет обновлять базовую частотность Yandex.Wordstat фраз в таблице, когда вы одновременно запускаете сбор данных из различных источников.
Принудительно очищать знак + из запросов для частотностей « » и «!». При снятии частотностей вида « » и «!», запрос заключается в кавычки. При этом знак +, если это оператор, теряет смысл — его нужно отфильтровать, что и позволяет эта опция. Если это часть запроса, фильтрация не нужна.
Не удалять запросы из таблицы при использовании строки быстрого поиска. По умолчанию после этого таблица очищается. Эта опция позволяет добивать недостающие фразы через строку быстрого поиска и не терять данные.
Получать частотности из APIShop.com. Вы можете зарегистрироваться в сервисе, пополнить баланс и получать данные о частотностях без капчи и задержек без обращений к Yandex.Wordstat.
Получать статистику через Yandex.Direct. Опция позволяет снимать статистику Yandex.Wordstat кроме данных сезонности через интерфейс Yandex.Direct. Это резервный режим на случай блокирования доступа к Yandex.Wordstat. Для его запуска нужно прописать доступ к аккаунтам Яндекс.Директа во вкладке «Yandex.Direct»..
Вкладка Yandex.Direct
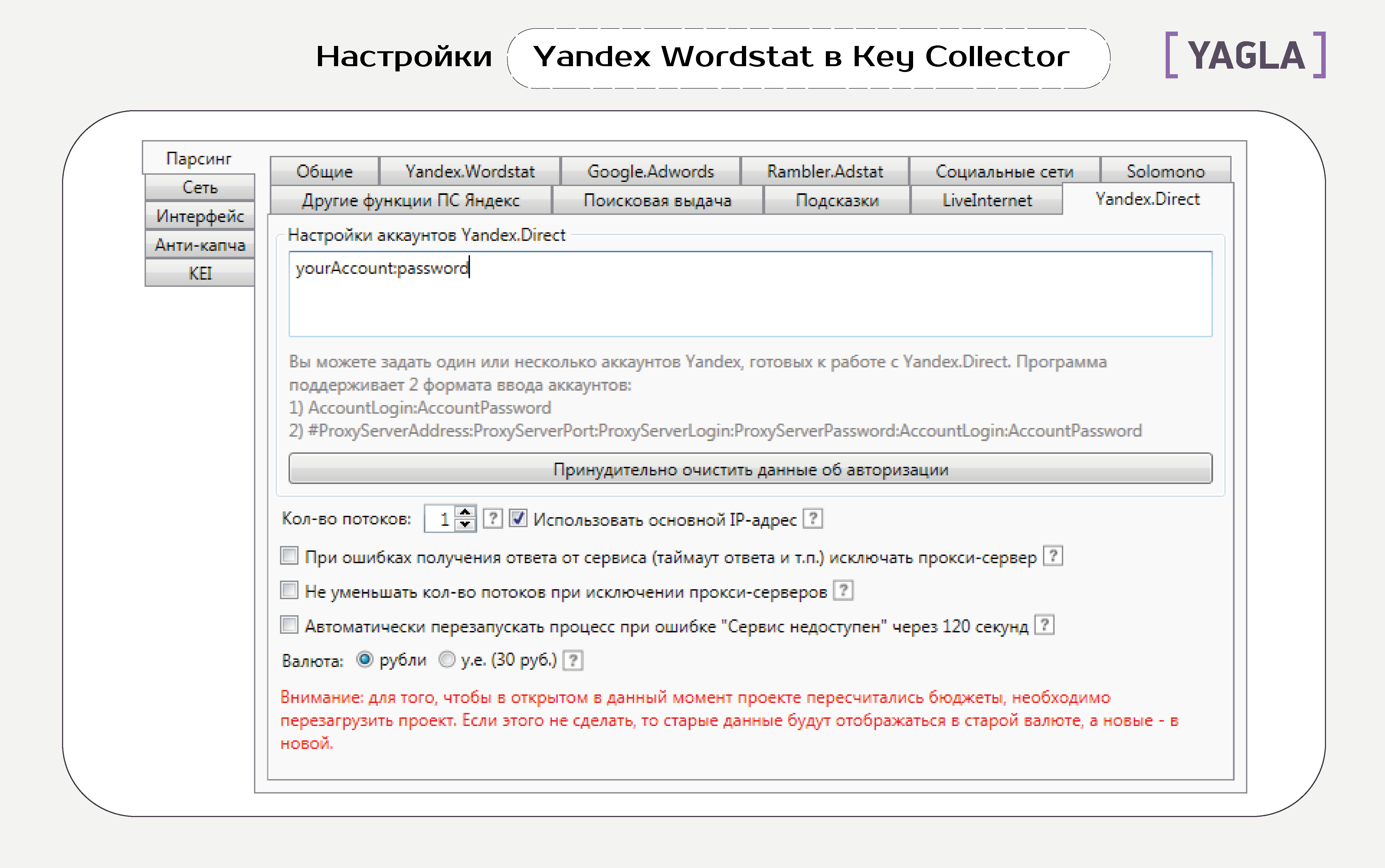
Минус: иногда этот способ выдает гораздо меньше информации в левой и правой колонке.
Внимание: доступ к Директу также могут заблокировать из-за автоматических запросов. Нужно использовать только специальные аккаунты Директа для сбора данных.
Автоматически перезапускать процесс при ошибке «Сервис недоступен» через 120 секунд. Иногда Yandex.Direct становится недоступным. Эта галочка включает повторную попытку собрать статистику.
Валюта. По умолчанию цены, бюджеты, стоимость клика в рублях. После изменения типа необходимо переоткрыть проект.
Вкладка «Подсказки»
Вкладка «Общие настройки»
СловоЕБ
Есть также бесплатная программа — СловоЕБ. Основное отличие от Key Collector — ограничение в источниках. Парсер работает только с левой и правой колонкой в Wordstat, Rambler.Adstat и поисковыми подсказками Яндекс и Google.
Для сравнения: Key Collector поддерживает всё вышеперечисленное, плюс Google Ads, подсказки Mail, Wordstat полностью и системы аналитики Google Analytics, Яндекс.Метрика, LiveInternet.
Другие ограничения программы СловоЕБ:
- Проверяет частоту запросов только по Wordstat, а КК также по Yandex.Direct, Google.Ads, LiveInternet, Rambler.Adstat, APIShop.com;
- Оценивает конкурентность запросов для Яндекс и Google, в то время как в КК 4 формулы оценки KEI, которые можно менять вручную;
- Нет поиска конкурентов;
- Не сохраняет проекты в аккаунте;
- Экспортирует результаты только в csv.
Однако этого функционала вполне хватает для небольших проектов.
MOAB Tools
Еще альтернативный сервис — MOAB Tools. Этот парсер предлагает разные тарифы в зависимости от количества запросов.
Парсер слов анализирует подсказки Яндекса по каждому запросу из Вордстата, автоматически удаляет дубли и проверяет частотность по суммарному отчету. Интеграция с Key Collector позволяет делать это в одно нажатие кнопки и получать результат в КК с частотностью по каждой фразе.
В расширенных настройках можно выбрать способ сбора подсказок по устройству, глубине парсинга и способу сбора:
- Фразы
- Фразы и пробелы
- Фразы и цифры
и т.д.
Очистка СЯ от «мусора»
Покажем, как очистить семантику в парсере Key Collector.
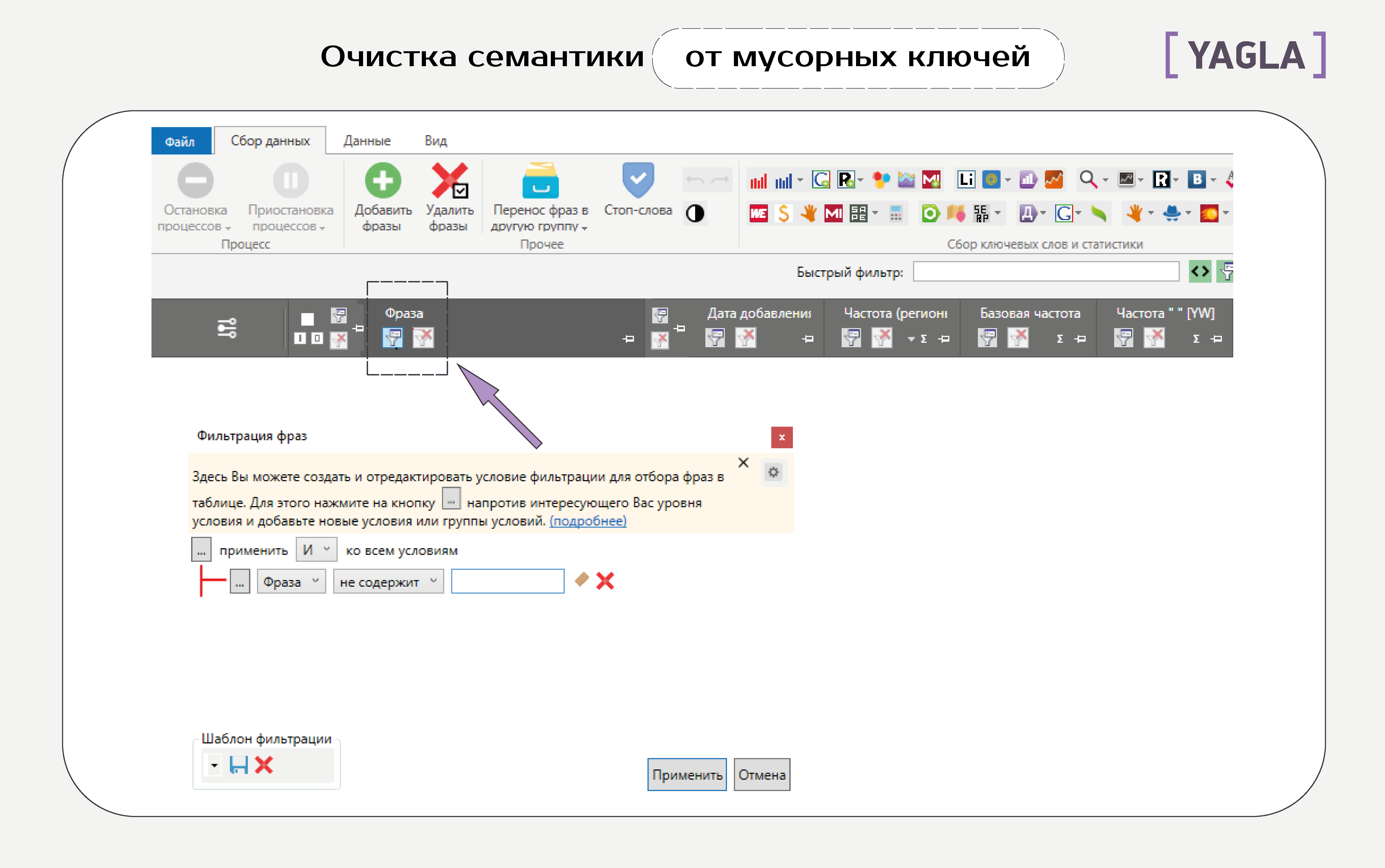
- Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации, задаем условие, как на скриншоте ниже, и пишем слова:
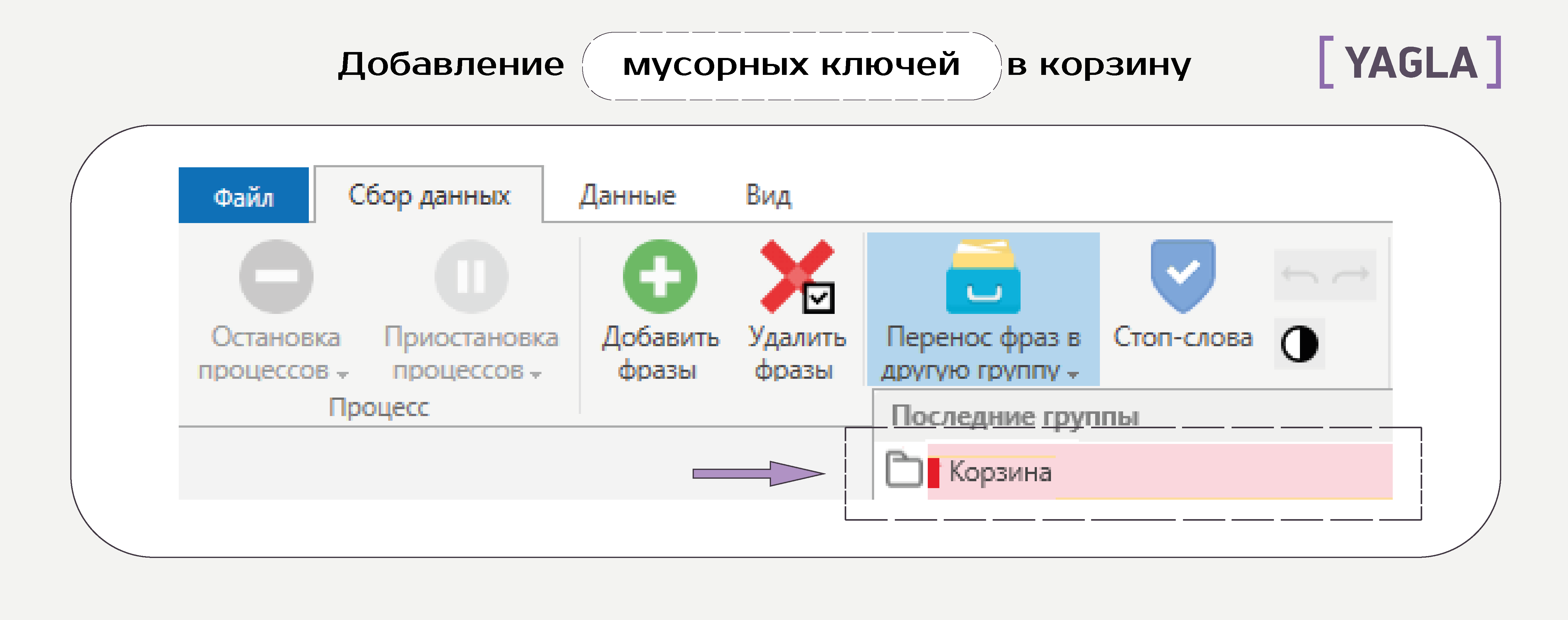
Отмечаем фразы и добавляем в корзину:
- Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
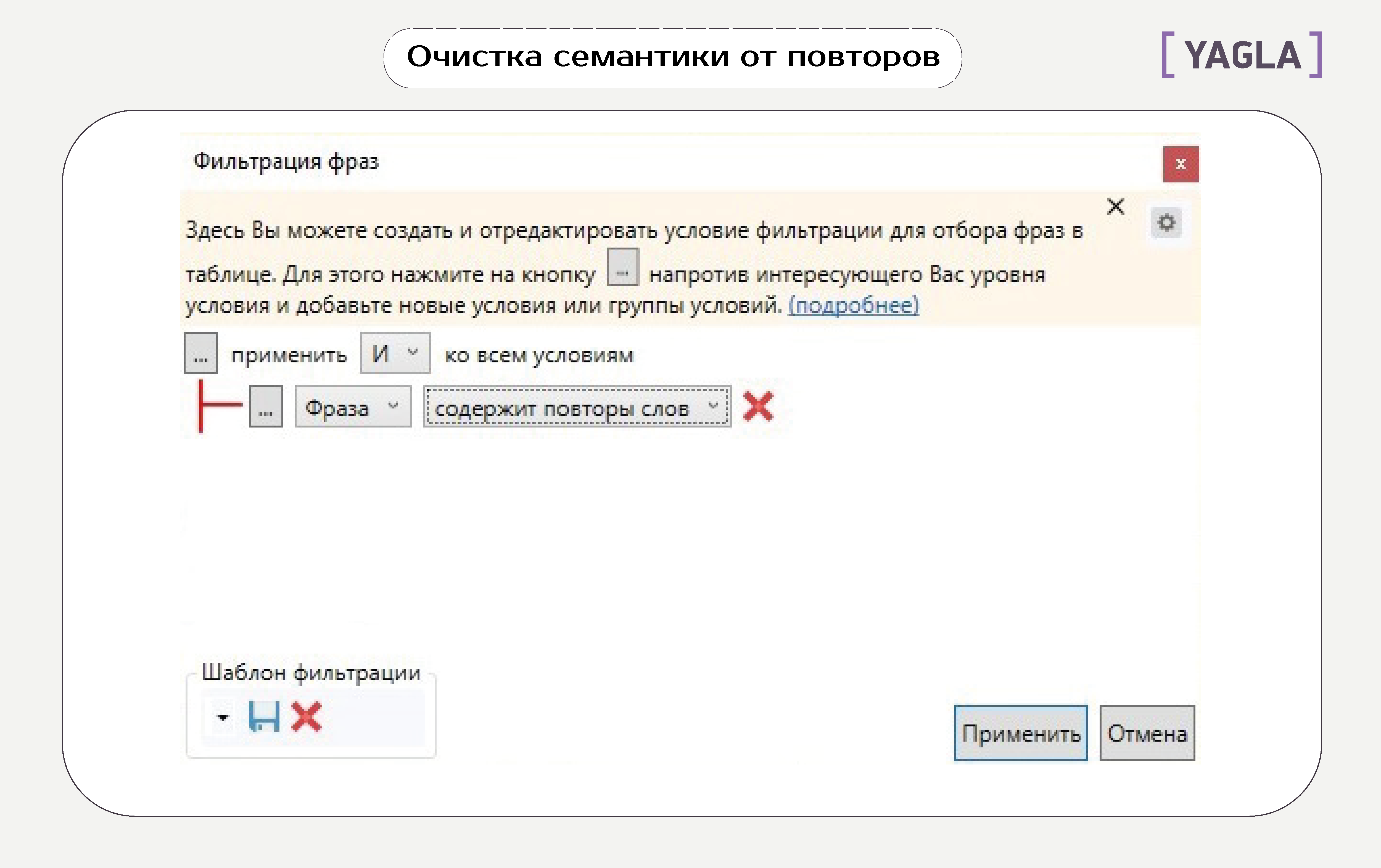
- Стоп-слова
К ним относятся информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.
В окне настроек добавляем фразы и разбиваем по группам:
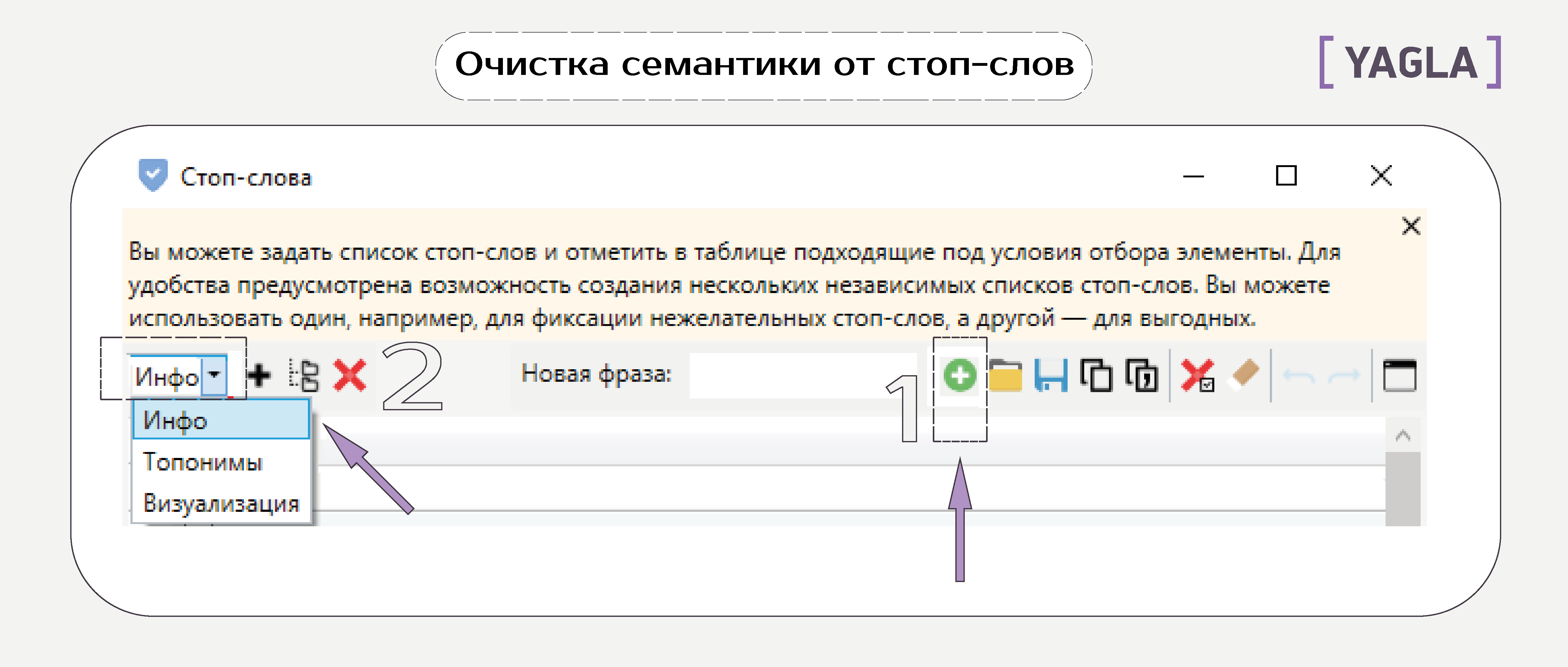
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:
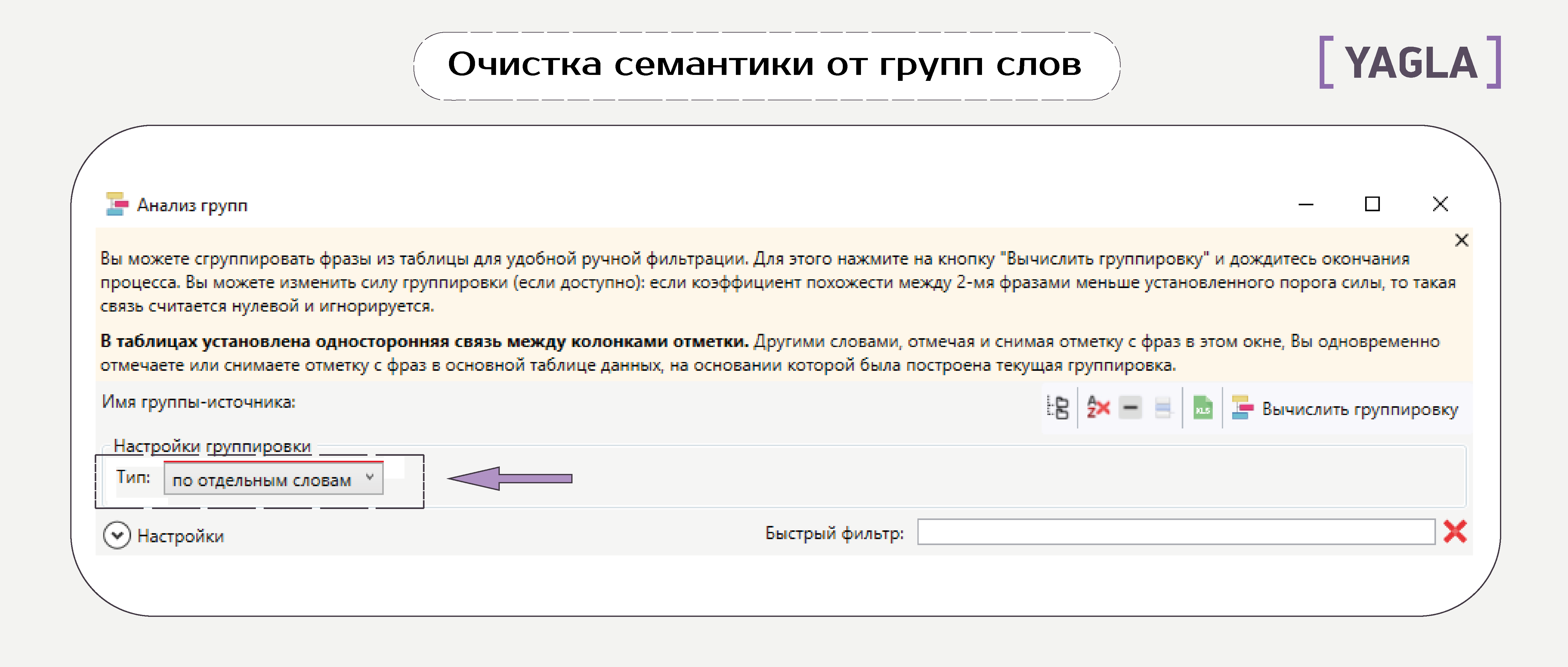
Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:

Далее — требования по частоте:
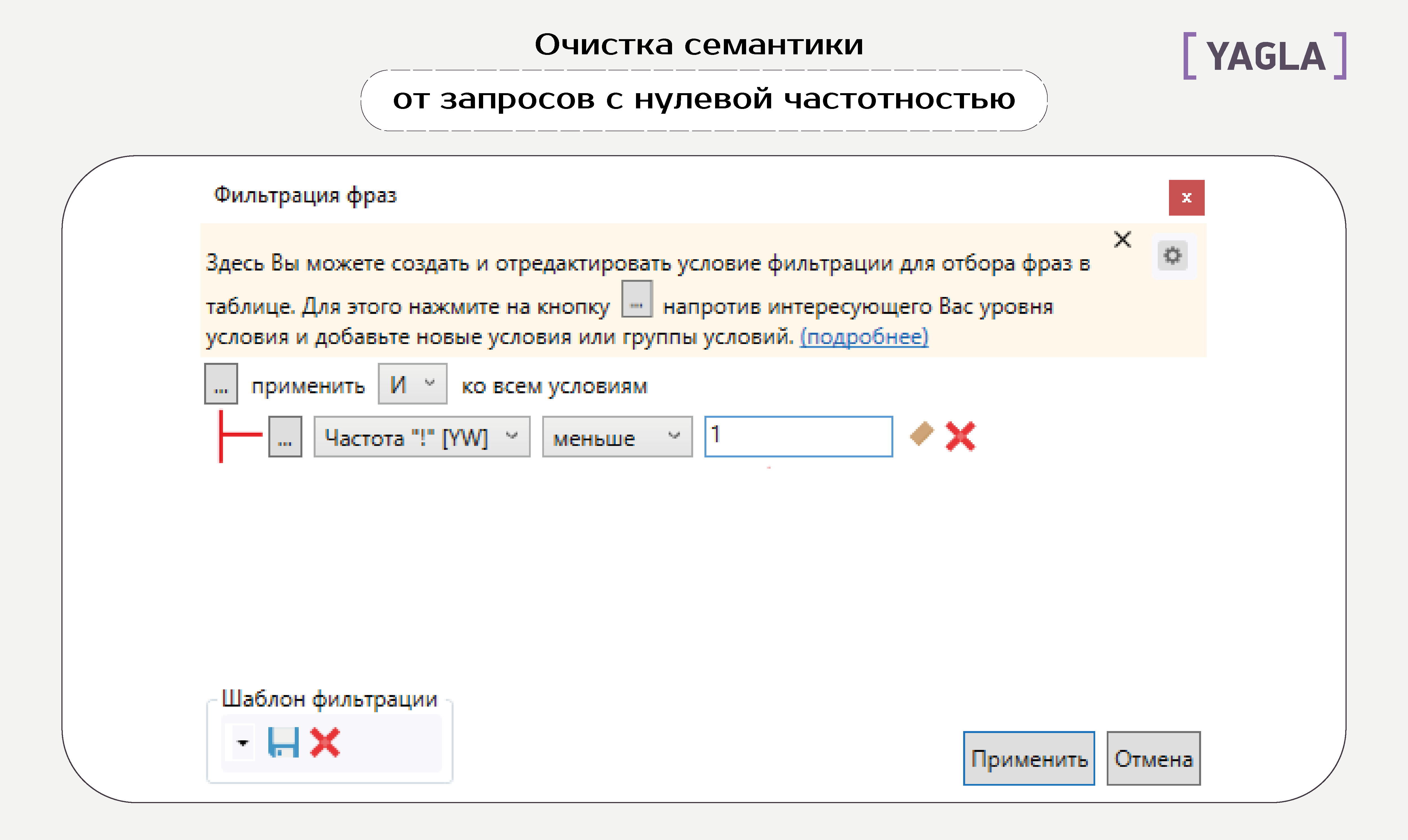
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись.
Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей, подсказок поисковиков и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе.
Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу.
Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха или осушка воздуха. Больше расширений можно насобирать по слову «осушка».
Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную.
Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
Метод перемножения
Шаг 1: расширения масок
Добавляем к базовым маскам расширения из одного слова, чтобы уточнить запрос по разным характеристикам в зависимости от специфики продукта:
- Тип транзакции — заказать, купить, сделать
- Кто оказывает услугу — подрядчик, фирма
- Качество — долговечный, красивый
- Цена — стоимость, расценки, прайс
- Гео
- Сервис — гарантия, срок, быстро, предоплата
- Цель — родителям, детям, для себя
Какие категории использовать — решаете сами. Варианты можно брать с сайтов конкурентов, из подсказок Яндекса и Гугла, словарей синонимов, тематических форумов и блогов — всё, где можно найти идеи о том, что именно в продукте интересует целевую аудиторию. Это могут быть синонимы, жаргоны, специфическая лексика и т.д.
Всё заносим для удобства в Excel. Получаем по каждому базису примерно такую таблицу:
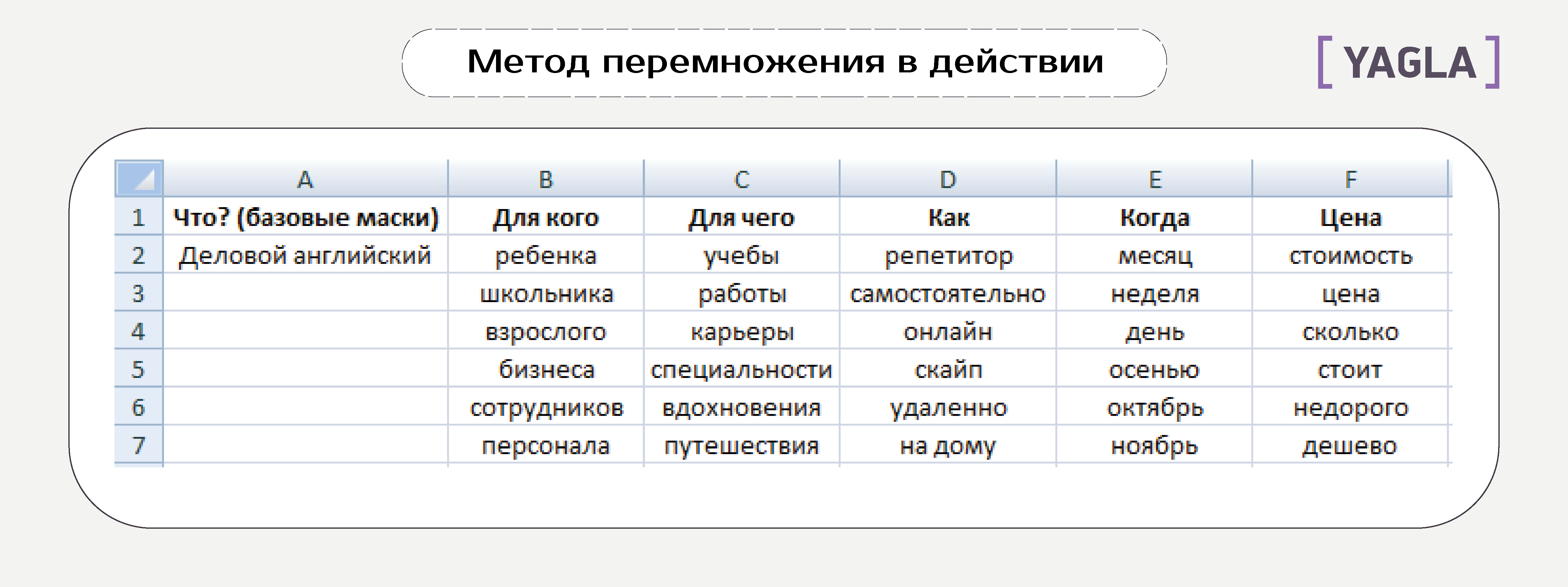
Принцип: 1 ячейка = 1 слово.
Шаг 2: перемножение
Перемножаем первый столбец с остальными по очереди в любом сервисе генерирования ключевых слов:
Результаты переносим на отдельный лист, удаляем нецелевые и ультранизкочастотные запросы.
Чек-лист по оптимизации семантического ядра в Яндекс.Директ
После того, как вы собрали первичный массив ключевых фраз, нужно удалить из них:
- Запросы, которые не соответствуют продукту. Например, если вы продаете промышленные светильники, удаляете всё, что связано со светильниками для дома
- Точные дубли
- Стоп-слова
- Фразы с нулевой частотностью
- «Холодные» запросы
- Неочевидные минус-слова
Ключевики для рекламных кампаний готовы. Следующий этап — группировка ключевых слов и создание групп объявлений. Об этом — в следующей статье.
4 причины, почему стоит начать генерировать лиды через Google Display Network Статья
Список ведущих маркетплейсов России и как на них заработать Статья
Как предпринимателю работать с маркетологами Статья
Сбер обновил GigaChat Audio: модель считывает интонацию и запоминает факты из диалогов Статья
Как обойти зарубежных селлеров на Wildberries без демпинга за счет локального визуала Статья
Реферальная программа: что это и как заработать на реферальных ссылках Статья
Переписки и документы пользователей Claude попали в поиск Google Статья
Кейс ASO для «Горздрава» и «36,6»: органика +50 %, ДРР -61,8 % Статья
Кейс: 149 заявок за 3 месяца в B2B-проектировании. Почему реклама не равно продажи? Статья





